Amazon scraping
Application de monitoring des produits sur Amazon avec scraping automatisé et alertes en temps réel.
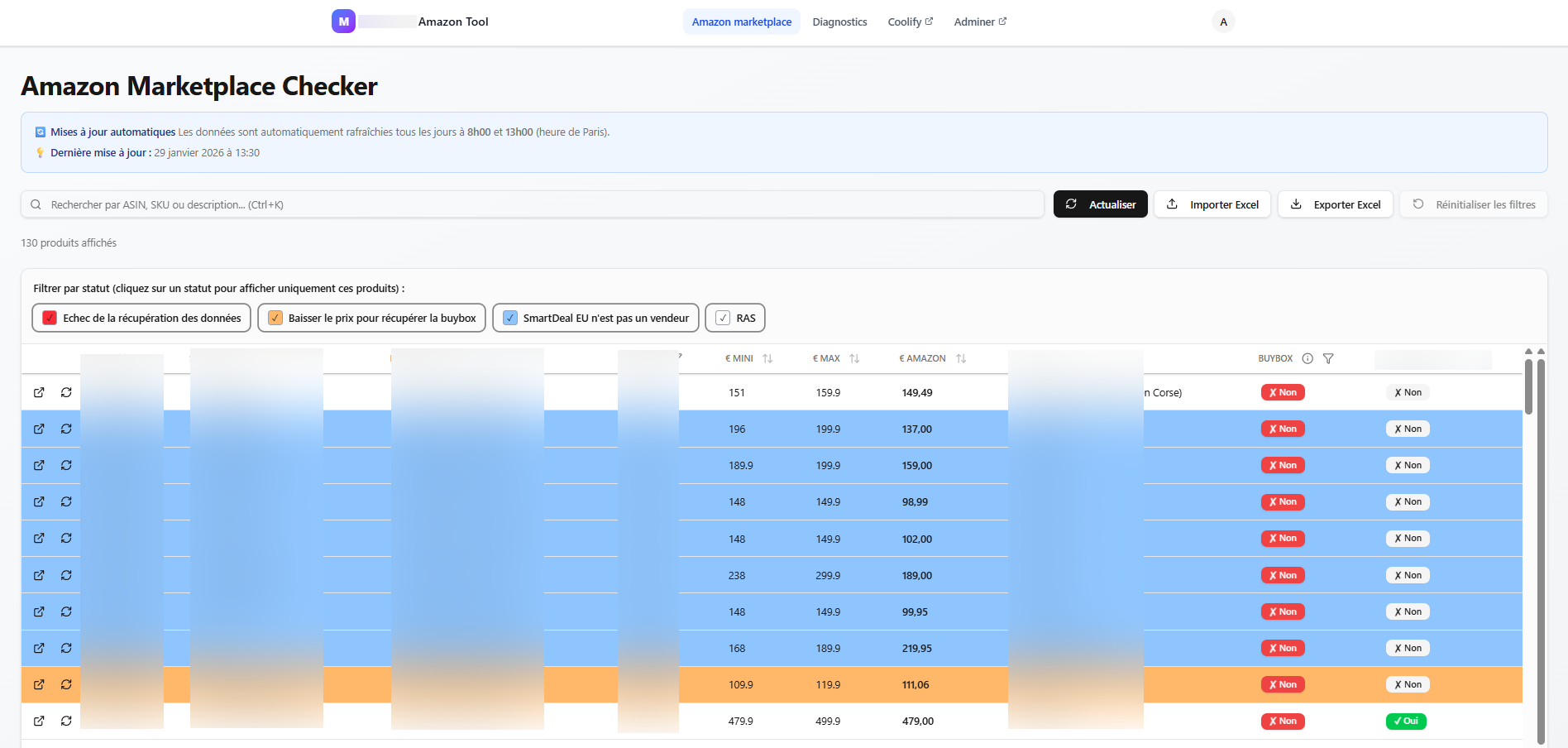
Problématique
Le client, vendeur sur Amazon France, avait besoin d'un outil interne pour surveiller son catalogue de plusieurs centaines de produits. L'enjeu principal : suivre en temps réel l'évolution des prix, la disponibilité des stocks et le positionnement par rapport aux concurrents sur la Buy Box. Sans outil dédié, cette veille manuelle était impossible à maintenir. La solution devait également contourner les protections anti-bot d'Amazon pour collecter les données de manière fiable, tout en générant des rapports Excel exploitables par l'équipe commerciale.
Solution technique
L'application adopte une architecture microservices Docker orchestrant 4 services distincts :
- Frontend Next.js 16 avec TanStack Query pour le cache client et Tailwind CSS
- API REST NestJS 11 gérant l'authentification (Passport JWT) et la logique métier (TypeORM)
- Service Browserless (Chromium headless + Playwright) pour le scraping
- Service Cron dédié déclenchant les rafraîchissements automatiques
Le scraping Amazon nécessite une stratégie anti-détection robuste :
- Rotation de User-Agents et headers réalistes
- Délais aléatoires entre les requêtes
- Mode stealth Playwright pour contourner les fingerprints
La couche données s'appuie sur PostgreSQL pour la persistance des produits et Redis pour le cache des données scrapées. L'ensemble est déployé sur OVH via Coolify, permettant un contrôle total de l'infrastructure.